
大家好,又见面了,我是你们的朋友全栈君。
一、运行原理
来看一个流程图:

解释如下:
二、

在上图中,箭头交叉处形成一个stage,其中伴随有shuffle操作。这些算子(如groupby、join)属于Action中的算子,而map、union则属于Transformation中的算子。
理解算子的含义:
Hadoop只有map和Reduce两个算子,而Spark提供了许多算子:
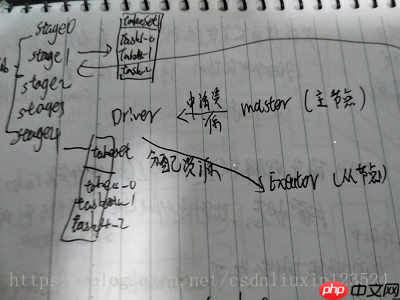
如上图所示,一个Job被拆分成若干个stage,每个stage执行一些计算,产生一些中间结果,最终生成这个Job的计算结果。每个stage是一个taskset,包含若干个task。Task是Spark中最小的工作单元,在一个executor(执行器)上完成一个特定任务。
三、窄依赖与宽依赖的判断方式,这里提供三种:
窄依赖:一个父RDD的一个partition最多被一个子RDD的一个partition使用。 宽依赖:一个父RDD的一个partition被多个子RDD的partition使用。 是否会发生shuffle操作,宽依赖会发生shuffle操作。总结1、2,一个partition的结果只被一个子partition使用,相当于没有发生shuffle操作。也可以看有没有发生combine操作,不同的partitions被多个子RDD使用,必然发生合并操作。
四、理解RDD是什么:全名“弹性分布式数据集”
可以类比理解为,HDFS上文件分片后的状态。例如,使用splitline()按行分割,则一行就是一个RDD。RDD是不可改变的分布式集合对象,因为它是加载的文件,显然我们不能对HDFS上的文件进行增删改操作。如val lines=sc.textFile("/home/aa.txt"),这里的lines即为RDDs。
如果aa.txt文件很大,按照HDFS的文件写入方式,我们知道aa.txt会被按照64MB的块大小放到不同的datanode节点上。在执行算子时,在各个节点上分别处理各自的数据,但我们操作的对象都是lines这个变量,因此lines也是这些节点数据的集合,即RDDs。
五、RDDs创建的两种方式:1. val rdds=sc.textFile();2. 并行化处理,创建一个类似Array的容器,val Rdds=sc.parallelize(Array(1,2,3,4),4)(注意,第二个参数4是partitions的个数)。
六、RDD.persist():持久化

十天学会易语言图解教程用图解的方式对易语言的使用方法和操作技巧作了生动、系统的讲解。需要的朋友们可以下载看看吧!全书分十章,分十天讲完。 第一章是介绍易语言的安装,以及运行后的界面。同时介绍一个非常简单的小程序,以帮助用户入门学习。最后介绍编程的输入方法,以及一些初学者会遇到的常见问题。第二章将接触一些具体的问题,如怎样编写一个1+2等于几的程序,并了解变量的概念,变量的有效范围,数据类型等知识。其后,您将跟着本书,编写一个自己的MP3播放器,认识窗口、按钮、编辑框三个常用组件。以认识命令及事件子程序。第
 3
3

默认情况下,每次在RDDs上进行action操作时,Spark都会重新计算RDDs。如果想重复利用一个RDDs,可以使用RDD.persist()。例如,对于同一个lines,如果我要进行一系列转换,然后使用count计算,如果我还想接着计算reduce,那么持久化就会利用前面的count的缓存数据来计算reduce。最后,可以使用unpersist()方法从缓存中移除。
七、RDDs的血统关系图:Spark维护者RDDs之间的依赖关系的创建关系,称为血统关系图。Spark使用血统关系图来计算每个RDD的需求和恢复丢失的数据。

上面是一个简单的血统图,优势在于知道数据的操作记录,如果其中某一步骤的RDD丢失了,那么可以根据血统关系图知道数据是如何来的,可以正向也可以反向,从而恢复数据。
八、延迟计算(lazy Evaluation):Spark对RDDs的计算是在它们第一次使用action操作时进行的,通俗地说,就是只有在数据被必要使用时才去加载,类似于Java的懒加载。例如,我们使用transformation对数据进行转换,但如果最后我们并没有使用转换后的数据来计算结果,这样岂不是白白耗费资源了吗?在大数据中,这一点尤为显著。那么,如何知道在使用时再去执行呢?Spark内部有一个metadata表会记录转换的操作记录。
九、RDD操作函数分为Transformation和Action两类:
(1)Transformation是转换的意思,顾名思义就是把数据从一种形式转变成另一种形式,可以理解为转成方便我们查看的形式,例如把一长串的字符串转成JSON树状图。
(2)Action是执行的意思,Spark提供了许多算子,伴随DAG图。
(3)两个可以理解为对应Hadoop中的map和reduce操作。
(4)没有action操作,单单转换是没有意义的。
十、Spark并行化就是执行了parallelize()方法,例如:sc.parallelize(array)。
十一、sparkContext是一个对象,代表与一个集群的连接。
sc.textFile()即为加载对象。
十二、再理解一下shuffle过程:将不同partition下相同的key聚集到一个partition下,导致数据在内存中的重新分布。这也就是所谓的打乱、洗牌。
Shuffle过程分为两个阶段:shuffle write和shuffle fetch。Shuffle write将shuffle MapTask任务产生的中间结果缓存到内存中,shuffle fetch获取shuffleMapTask缓存的中间结果进行shuffleReduceTask计算。
发布者:全栈程序员栈长,转载请注明出处:https://www.php.cn/link/381476ddd3f32431fcab00d7cc68d791 原文链接:https://www.php.cn/link/c8377ad2a50fb65de28b11cfc628d75c
以上就是spark运行原理简单介绍和一些总结的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 196
196























